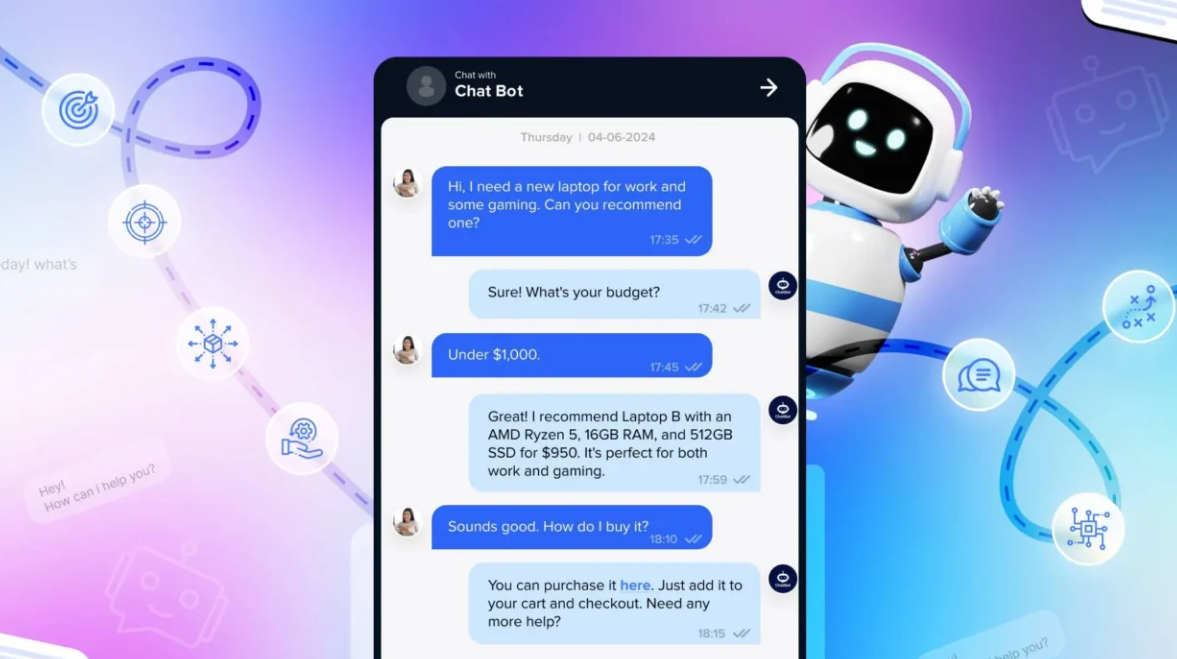
Prova l'IA sul TUO sito web in 60 secondi
Guarda come la nostra IA analizza istantaneamente il tuo sito web e crea un chatbot personalizzato - senza registrazione. Inserisci semplicemente il tuo URL e guarda come funziona!
Pronto in 60 secondi
Nessuna codifica richiesta
100% sicuro
Il paradosso della privacy degli assistenti AI moderni
Li abbiamo accolti nelle nostre case, nei nostri uffici e nelle nostre tasche. Poniamo loro domande durante la giornata, chiediamo loro di riprodurre le nostre canzoni preferite e ci fidiamo di loro per controllare le nostre smart home. Le interfacce conversazionali basate sull'intelligenza artificiale sono diventate così integrate nella vita quotidiana che molti di noi interagiscono con più assistenti AI decine di volte al giorno senza pensarci due volte.
Tuttavia, dietro queste interazioni fluide si cela un complesso panorama della privacy che pochi utenti comprendono appieno. La natura stessa dell'intelligenza artificiale conversazionale crea una tensione fondamentale: questi sistemi necessitano di dati – spesso personali, a volte sensibili – per funzionare efficacemente, ma questa stessa raccolta di dati crea implicazioni significative per la privacy che non possono essere ignorate.
Questa tensione rappresenta ciò che i ricercatori sulla privacy chiamano il "paradosso funzionalità-privacy". Per fornire risposte personalizzate e contestualmente rilevanti, gli assistenti AI devono conoscere te. Le tue preferenze, la tua cronologia, la tua posizione e le tue abitudini influenzano le interazioni più utili. Ma ogni informazione raccolta rappresenta una potenziale esposizione alla privacy che deve essere gestita e protetta con attenzione.
La posta in gioco non è mai stata così alta. Man mano che le interfacce conversazionali si evolvono da semplici comandi ("Imposta un timer per 10 minuti") a interazioni complesse e contestualizzate ("Ricordami di sollevare quel problema dell'email della settimana scorsa quando incontrerò Sarah domani"), le implicazioni per la privacy crescono esponenzialmente. Questi sistemi non si limitano più a elaborare richieste isolate, ma costruiscono modelli utente completi che abbracciano più ambiti della nostra vita. Per sviluppatori, aziende e utenti che si muovono in questo panorama, comprendere le sfide specifiche per la privacy dell'IA conversazionale è il primo passo verso un'implementazione e un utilizzo responsabili. Esploriamo questo terreno complesso e le strategie emergenti per bilanciare funzionalità potenti con una solida protezione della privacy.
Tuttavia, dietro queste interazioni fluide si cela un complesso panorama della privacy che pochi utenti comprendono appieno. La natura stessa dell'intelligenza artificiale conversazionale crea una tensione fondamentale: questi sistemi necessitano di dati – spesso personali, a volte sensibili – per funzionare efficacemente, ma questa stessa raccolta di dati crea implicazioni significative per la privacy che non possono essere ignorate.
Questa tensione rappresenta ciò che i ricercatori sulla privacy chiamano il "paradosso funzionalità-privacy". Per fornire risposte personalizzate e contestualmente rilevanti, gli assistenti AI devono conoscere te. Le tue preferenze, la tua cronologia, la tua posizione e le tue abitudini influenzano le interazioni più utili. Ma ogni informazione raccolta rappresenta una potenziale esposizione alla privacy che deve essere gestita e protetta con attenzione.
La posta in gioco non è mai stata così alta. Man mano che le interfacce conversazionali si evolvono da semplici comandi ("Imposta un timer per 10 minuti") a interazioni complesse e contestualizzate ("Ricordami di sollevare quel problema dell'email della settimana scorsa quando incontrerò Sarah domani"), le implicazioni per la privacy crescono esponenzialmente. Questi sistemi non si limitano più a elaborare richieste isolate, ma costruiscono modelli utente completi che abbracciano più ambiti della nostra vita. Per sviluppatori, aziende e utenti che si muovono in questo panorama, comprendere le sfide specifiche per la privacy dell'IA conversazionale è il primo passo verso un'implementazione e un utilizzo responsabili. Esploriamo questo terreno complesso e le strategie emergenti per bilanciare funzionalità potenti con una solida protezione della privacy.
Capire cosa sta realmente accadendo con i tuoi dati vocali
Quando interagisci con un sistema di intelligenza artificiale conversazionale, cosa succede effettivamente ai tuoi dati? Il percorso è più complesso, e spesso più esteso, di quanto molti utenti credano.
Il processo inizia in genere con l'acquisizione dei dati. I sistemi vocali convertono l'audio in segnali digitali, mentre le interfacce testuali acquisiscono gli input digitati. Questi dati grezzi vengono quindi sottoposti a diverse fasi di elaborazione che possono includere:
Conversione da voce a testo per gli input vocali
Elaborazione del linguaggio naturale per determinare l'intento
Analisi del contesto che può incorporare interazioni precedenti
Generazione di risposte basata su modelli di intelligenza artificiale addestrati
Elaborazione aggiuntiva per la personalizzazione
Archiviazione delle interazioni per il miglioramento del sistema
Ogni fase presenta distinte considerazioni sulla privacy. Ad esempio, dove avviene la conversione da voce a testo: sul tuo dispositivo o su server remoti? Le registrazioni della tua voce vengono archiviate e, in tal caso, per quanto tempo? Chi potrebbe avere accesso a queste registrazioni? Il sistema è in ascolto continuo o solo dopo una parola di attivazione?
I principali fornitori hanno approcci diversi a queste domande. Alcuni elaborano tutti i dati nel cloud, mentre altri eseguono l'elaborazione iniziale sul dispositivo per limitare la trasmissione dei dati. Le policy di archiviazione variano notevolmente, dalla conservazione indefinita all'eliminazione automatica dopo periodi specifici. I controlli di accesso spaziano da una rigida limitazione all'utilizzo autorizzato da parte di revisori umani per il miglioramento della qualità.
La realtà è che, anche quando le aziende dispongono di solide policy sulla privacy, la complessità intrinseca di questi sistemi rende difficile per gli utenti mantenere una chiara visibilità su come vengono utilizzati i loro dati. Recenti rivelazioni su revisori umani che ascoltano le registrazioni degli assistenti vocali hanno sorpreso molti utenti che presumevano che le loro interazioni rimanessero completamente private o fossero elaborate solo da sistemi automatizzati.
A questa complessità si aggiunge la natura distribuita dei moderni assistenti AI. Quando chiedi al tuo smart speaker informazioni sui ristoranti nelle vicinanze, tale richiesta potrebbe interagire con più sistemi – l'IA principale dell'assistente, i servizi di mappatura, i database dei ristoranti, le piattaforme di recensioni – ognuno con le proprie pratiche sui dati e implicazioni sulla privacy.
Affinché gli utenti possano fare scelte consapevoli, una maggiore trasparenza in questi processi è essenziale. Alcuni provider hanno compiuto progressi in questa direzione, offrendo spiegazioni più chiare sulle pratiche sui dati, controlli sulla privacy più granulari e opzioni per rivedere ed eliminare i dati storici. Tuttavia, permangono lacune significative nell'aiutare gli utenti a comprendere veramente le implicazioni sulla privacy delle loro interazioni quotidiane con l'intelligenza artificiale.
Il processo inizia in genere con l'acquisizione dei dati. I sistemi vocali convertono l'audio in segnali digitali, mentre le interfacce testuali acquisiscono gli input digitati. Questi dati grezzi vengono quindi sottoposti a diverse fasi di elaborazione che possono includere:
Conversione da voce a testo per gli input vocali
Elaborazione del linguaggio naturale per determinare l'intento
Analisi del contesto che può incorporare interazioni precedenti
Generazione di risposte basata su modelli di intelligenza artificiale addestrati
Elaborazione aggiuntiva per la personalizzazione
Archiviazione delle interazioni per il miglioramento del sistema
Ogni fase presenta distinte considerazioni sulla privacy. Ad esempio, dove avviene la conversione da voce a testo: sul tuo dispositivo o su server remoti? Le registrazioni della tua voce vengono archiviate e, in tal caso, per quanto tempo? Chi potrebbe avere accesso a queste registrazioni? Il sistema è in ascolto continuo o solo dopo una parola di attivazione?
I principali fornitori hanno approcci diversi a queste domande. Alcuni elaborano tutti i dati nel cloud, mentre altri eseguono l'elaborazione iniziale sul dispositivo per limitare la trasmissione dei dati. Le policy di archiviazione variano notevolmente, dalla conservazione indefinita all'eliminazione automatica dopo periodi specifici. I controlli di accesso spaziano da una rigida limitazione all'utilizzo autorizzato da parte di revisori umani per il miglioramento della qualità.
La realtà è che, anche quando le aziende dispongono di solide policy sulla privacy, la complessità intrinseca di questi sistemi rende difficile per gli utenti mantenere una chiara visibilità su come vengono utilizzati i loro dati. Recenti rivelazioni su revisori umani che ascoltano le registrazioni degli assistenti vocali hanno sorpreso molti utenti che presumevano che le loro interazioni rimanessero completamente private o fossero elaborate solo da sistemi automatizzati.
A questa complessità si aggiunge la natura distribuita dei moderni assistenti AI. Quando chiedi al tuo smart speaker informazioni sui ristoranti nelle vicinanze, tale richiesta potrebbe interagire con più sistemi – l'IA principale dell'assistente, i servizi di mappatura, i database dei ristoranti, le piattaforme di recensioni – ognuno con le proprie pratiche sui dati e implicazioni sulla privacy.
Affinché gli utenti possano fare scelte consapevoli, una maggiore trasparenza in questi processi è essenziale. Alcuni provider hanno compiuto progressi in questa direzione, offrendo spiegazioni più chiare sulle pratiche sui dati, controlli sulla privacy più granulari e opzioni per rivedere ed eliminare i dati storici. Tuttavia, permangono lacune significative nell'aiutare gli utenti a comprendere veramente le implicazioni sulla privacy delle loro interazioni quotidiane con l'intelligenza artificiale.
Il panorama normativo: in evoluzione ma incoerente
L'IA conversazionale opera in un contesto normativo in rapida evoluzione e al tempo stesso frustrantemente frammentato. Diverse regioni hanno adottato approcci diversi alla privacy dei dati, che incidono direttamente sulle modalità di progettazione e implementazione delle interfacce conversazionali.
Il Regolamento generale sulla protezione dei dati (GDPR) dell'Unione Europea rappresenta uno dei quadri normativi più completi, stabilendo principi che influenzano significativamente l'IA conversazionale:
Il requisito di un consenso specifico e informato prima del trattamento dei dati personali;
I principi di minimizzazione dei dati, che limitano la raccolta al necessario;
La limitazione delle finalità, che limita l'utilizzo dei dati oltre le intenzioni dichiarate;
Il diritto di accesso ai dati personali detenuti dalle aziende;
Il diritto all'oblio (cancellazione dei dati su richiesta);
Requisiti per la portabilità dei dati tra i servizi
Questi requisiti presentano sfide particolari per l'IA conversazionale, che spesso si basa su un'ampia raccolta di dati e può avere difficoltà a rispettare una chiara limitazione delle finalità quando i sistemi sono progettati per gestire richieste varie e imprevedibili.
Negli Stati Uniti, la normativa sulla privacy rimane più frammentata, con il California Consumer Privacy Act (CCPA) e il suo successore, il California Privacy Rights Act (CPRA), che stabiliscono le più severe tutele a livello statale. Queste normative garantiscono ai residenti in California diritti simili a quelli previsti dal GDPR, tra cui l'accesso alle informazioni personali e il diritto alla cancellazione dei dati. Altri stati hanno seguito con le proprie normative, creando un mosaico di requisiti in tutto il paese.
Le normative specializzate aggiungono ulteriore complessità. Nel contesto sanitario, le normative HIPAA negli Stati Uniti impongono requisiti rigorosi per il trattamento delle informazioni mediche. Per i servizi rivolti ai minori, il COPPA stabilisce ulteriori tutele che limitano la raccolta e l'utilizzo dei dati.
La natura globale della maggior parte dei servizi di intelligenza artificiale conversazionale implica che le aziende debbano in genere progettare in base alle normative applicabili più severe, gestendo al contempo la conformità in più giurisdizioni. Questo panorama complesso crea sfide sia per le aziende consolidate che devono destreggiarsi tra requisiti diversi, sia per le startup con risorse legali limitate.
Per gli utenti, il contesto normativo incoerente implica che le tutele della privacy possano variare significativamente a seconda del luogo in cui vivono. Chi vive in regioni con leggi severe sulla protezione dei dati gode generalmente di maggiori diritti in merito ai dati generati dall'IA conversazionale, mentre altri potrebbero godere di minori tutele legali. Il panorama normativo continua a evolversi, con nuove normative in fase di sviluppo in molte regioni che affrontano specificamente la governance dell'IA. Questi quadri normativi emergenti potrebbero fornire approcci più mirati alle specifiche sfide dell'IA conversazionale in materia di privacy, stabilendo potenzialmente standard più chiari per il consenso, la trasparenza e la gestione dei dati in questi sistemi sempre più importanti.
Il Regolamento generale sulla protezione dei dati (GDPR) dell'Unione Europea rappresenta uno dei quadri normativi più completi, stabilendo principi che influenzano significativamente l'IA conversazionale:
Il requisito di un consenso specifico e informato prima del trattamento dei dati personali;
I principi di minimizzazione dei dati, che limitano la raccolta al necessario;
La limitazione delle finalità, che limita l'utilizzo dei dati oltre le intenzioni dichiarate;
Il diritto di accesso ai dati personali detenuti dalle aziende;
Il diritto all'oblio (cancellazione dei dati su richiesta);
Requisiti per la portabilità dei dati tra i servizi
Questi requisiti presentano sfide particolari per l'IA conversazionale, che spesso si basa su un'ampia raccolta di dati e può avere difficoltà a rispettare una chiara limitazione delle finalità quando i sistemi sono progettati per gestire richieste varie e imprevedibili.
Negli Stati Uniti, la normativa sulla privacy rimane più frammentata, con il California Consumer Privacy Act (CCPA) e il suo successore, il California Privacy Rights Act (CPRA), che stabiliscono le più severe tutele a livello statale. Queste normative garantiscono ai residenti in California diritti simili a quelli previsti dal GDPR, tra cui l'accesso alle informazioni personali e il diritto alla cancellazione dei dati. Altri stati hanno seguito con le proprie normative, creando un mosaico di requisiti in tutto il paese.
Le normative specializzate aggiungono ulteriore complessità. Nel contesto sanitario, le normative HIPAA negli Stati Uniti impongono requisiti rigorosi per il trattamento delle informazioni mediche. Per i servizi rivolti ai minori, il COPPA stabilisce ulteriori tutele che limitano la raccolta e l'utilizzo dei dati.
La natura globale della maggior parte dei servizi di intelligenza artificiale conversazionale implica che le aziende debbano in genere progettare in base alle normative applicabili più severe, gestendo al contempo la conformità in più giurisdizioni. Questo panorama complesso crea sfide sia per le aziende consolidate che devono destreggiarsi tra requisiti diversi, sia per le startup con risorse legali limitate.
Per gli utenti, il contesto normativo incoerente implica che le tutele della privacy possano variare significativamente a seconda del luogo in cui vivono. Chi vive in regioni con leggi severe sulla protezione dei dati gode generalmente di maggiori diritti in merito ai dati generati dall'IA conversazionale, mentre altri potrebbero godere di minori tutele legali. Il panorama normativo continua a evolversi, con nuove normative in fase di sviluppo in molte regioni che affrontano specificamente la governance dell'IA. Questi quadri normativi emergenti potrebbero fornire approcci più mirati alle specifiche sfide dell'IA conversazionale in materia di privacy, stabilendo potenzialmente standard più chiari per il consenso, la trasparenza e la gestione dei dati in questi sistemi sempre più importanti.
Le sfide tecniche dell'intelligenza artificiale conversazionale a tutela della privacy
Costruire un'IA conversazionale che rispetti la privacy mantenendo al contempo un'elevata funzionalità presenta sfide tecniche significative. Questi sistemi si sono tradizionalmente basati sull'elaborazione centralizzata nel cloud e su un'ampia raccolta di dati, approcci che possono entrare in conflitto con le migliori pratiche in materia di privacy.
Diverse sfide tecniche chiave si pongono all'intersezione tra IA conversazionale e privacy:
Elaborazione su dispositivo vs. Cloud Computing
Spostare l'elaborazione dal cloud al dispositivo (edge computing) può migliorare significativamente la privacy mantenendo i dati sensibili in locale. Tuttavia, questo approccio presenta notevoli limitazioni:
I dispositivi mobili e domestici dispongono di risorse di calcolo limitate rispetto all'infrastruttura cloud
I modelli di IA più grandi potrebbero non essere adatti ai dispositivi consumer
I modelli su dispositivo potrebbero fornire risposte di qualità inferiore senza accesso all'apprendimento centralizzato
I frequenti aggiornamenti dei modelli possono consumare una notevole quantità di larghezza di banda e spazio di archiviazione
Nonostante queste sfide, i progressi nella compressione dei modelli e nell'hardware specializzato per l'IA stanno rendendo l'elaborazione su dispositivo sempre più praticabile. Alcuni sistemi ora utilizzano approcci ibridi, eseguendo l'elaborazione iniziale localmente e inviando al cloud solo i dati necessari.
Machine Learning a tutela della privacy
Gli approcci tradizionali di machine learning si sono concentrati sulla raccolta centralizzata dei dati, ma stanno emergendo alternative incentrate sulla privacy:
L'apprendimento federato consente di addestrare i modelli su più dispositivi mantenendo i dati personali locali. Solo gli aggiornamenti dei modelli (non i dati degli utenti) vengono condivisi con i server centrali, proteggendo la privacy individuale e consentendo al contempo il miglioramento del sistema.
La privacy differenziale introduce rumore calcolato nei set di dati o nelle query per impedire l'identificazione degli individui, preservando al contempo la validità statistica per l'addestramento e l'analisi.
Il calcolo multi-parte sicuro consente l'analisi su più fonti di dati senza che nessuna delle parti debba rivelare i propri dati grezzi ad altri.
Queste tecniche sono promettenti, ma presentano compromessi in termini di efficienza computazionale, complessità di implementazione e talvolta minore accuratezza rispetto agli approcci tradizionali.
Strategie di minimizzazione dei dati
La progettazione incentrata sulla privacy richiede la raccolta dei soli dati necessari per la funzionalità prevista, ma definire il "necessario" per sistemi conversazionali flessibili presenta delle difficoltà:
Come possono i sistemi determinare in anticipo quale contesto potrebbe essere necessario per le interazioni future?
Quali informazioni di base sono necessarie per fornire esperienze personalizzate ma rispettose della privacy?
Come possono i sistemi bilanciare le esigenze di funzionalità immediate con la potenziale utilità futura?
Alcuni approcci si concentrano sulla conservazione dei dati a tempo limitato, memorizzando la cronologia delle interazioni solo per periodi definiti pertinenti ai modelli di utilizzo previsti. Altri enfatizzano il controllo dell'utente, consentendo agli individui di specificare quali dati storici mantenere o dimenticare.
Limiti dell'anonimizzazione
Le tecniche di anonimizzazione tradizionali spesso si rivelano inadeguate per i dati conversazionali, che contengono informazioni contestuali approfondite che possono facilitarne la reidentificazione:
I modelli linguistici e la scelta delle parole possono essere altamente identificativi
Le domande sulle circostanze personali possono rivelare dettagli identificabili anche quando vengono rimosse informazioni identificative dirette
L'effetto cumulativo di più interazioni può creare profili identificabili anche da scambi individuali apparentemente anonimi
La ricerca su tecniche di anonimizzazione avanzate specificamente progettate per i contenuti conversazionali continua, ma l'anonimizzazione perfetta preservando l'utilità rimane un obiettivo irraggiungibile.
Queste sfide tecniche evidenziano perché un'intelligenza artificiale conversazionale che garantisca la privacy richieda approcci radicalmente nuovi, anziché limitarsi ad applicare le tradizionali tecniche di privacy alle architetture di intelligenza artificiale esistenti. Il progresso richiede una profonda collaborazione tra ricercatori di intelligenza artificiale, esperti di privacy e architetti di sistema per sviluppare approcci che rispettino la privacy fin dalla progettazione, anziché come un fattore secondario.
Diverse sfide tecniche chiave si pongono all'intersezione tra IA conversazionale e privacy:
Elaborazione su dispositivo vs. Cloud Computing
Spostare l'elaborazione dal cloud al dispositivo (edge computing) può migliorare significativamente la privacy mantenendo i dati sensibili in locale. Tuttavia, questo approccio presenta notevoli limitazioni:
I dispositivi mobili e domestici dispongono di risorse di calcolo limitate rispetto all'infrastruttura cloud
I modelli di IA più grandi potrebbero non essere adatti ai dispositivi consumer
I modelli su dispositivo potrebbero fornire risposte di qualità inferiore senza accesso all'apprendimento centralizzato
I frequenti aggiornamenti dei modelli possono consumare una notevole quantità di larghezza di banda e spazio di archiviazione
Nonostante queste sfide, i progressi nella compressione dei modelli e nell'hardware specializzato per l'IA stanno rendendo l'elaborazione su dispositivo sempre più praticabile. Alcuni sistemi ora utilizzano approcci ibridi, eseguendo l'elaborazione iniziale localmente e inviando al cloud solo i dati necessari.
Machine Learning a tutela della privacy
Gli approcci tradizionali di machine learning si sono concentrati sulla raccolta centralizzata dei dati, ma stanno emergendo alternative incentrate sulla privacy:
L'apprendimento federato consente di addestrare i modelli su più dispositivi mantenendo i dati personali locali. Solo gli aggiornamenti dei modelli (non i dati degli utenti) vengono condivisi con i server centrali, proteggendo la privacy individuale e consentendo al contempo il miglioramento del sistema.
La privacy differenziale introduce rumore calcolato nei set di dati o nelle query per impedire l'identificazione degli individui, preservando al contempo la validità statistica per l'addestramento e l'analisi.
Il calcolo multi-parte sicuro consente l'analisi su più fonti di dati senza che nessuna delle parti debba rivelare i propri dati grezzi ad altri.
Queste tecniche sono promettenti, ma presentano compromessi in termini di efficienza computazionale, complessità di implementazione e talvolta minore accuratezza rispetto agli approcci tradizionali.
Strategie di minimizzazione dei dati
La progettazione incentrata sulla privacy richiede la raccolta dei soli dati necessari per la funzionalità prevista, ma definire il "necessario" per sistemi conversazionali flessibili presenta delle difficoltà:
Come possono i sistemi determinare in anticipo quale contesto potrebbe essere necessario per le interazioni future?
Quali informazioni di base sono necessarie per fornire esperienze personalizzate ma rispettose della privacy?
Come possono i sistemi bilanciare le esigenze di funzionalità immediate con la potenziale utilità futura?
Alcuni approcci si concentrano sulla conservazione dei dati a tempo limitato, memorizzando la cronologia delle interazioni solo per periodi definiti pertinenti ai modelli di utilizzo previsti. Altri enfatizzano il controllo dell'utente, consentendo agli individui di specificare quali dati storici mantenere o dimenticare.
Limiti dell'anonimizzazione
Le tecniche di anonimizzazione tradizionali spesso si rivelano inadeguate per i dati conversazionali, che contengono informazioni contestuali approfondite che possono facilitarne la reidentificazione:
I modelli linguistici e la scelta delle parole possono essere altamente identificativi
Le domande sulle circostanze personali possono rivelare dettagli identificabili anche quando vengono rimosse informazioni identificative dirette
L'effetto cumulativo di più interazioni può creare profili identificabili anche da scambi individuali apparentemente anonimi
La ricerca su tecniche di anonimizzazione avanzate specificamente progettate per i contenuti conversazionali continua, ma l'anonimizzazione perfetta preservando l'utilità rimane un obiettivo irraggiungibile.
Queste sfide tecniche evidenziano perché un'intelligenza artificiale conversazionale che garantisca la privacy richieda approcci radicalmente nuovi, anziché limitarsi ad applicare le tradizionali tecniche di privacy alle architetture di intelligenza artificiale esistenti. Il progresso richiede una profonda collaborazione tra ricercatori di intelligenza artificiale, esperti di privacy e architetti di sistema per sviluppare approcci che rispettino la privacy fin dalla progettazione, anziché come un fattore secondario.
Trasparenza e consenso: ripensare il controllo dell'utente
La natura conversazionale degli assistenti AI pone sfide uniche per i modelli tradizionali di trasparenza e consenso. Gli approcci standard, come le lunghe informative sulla privacy o le richieste di consenso una tantum, si rivelano particolarmente inadeguati in questo contesto. Diversi fattori complicano la trasparenza e il consenso per le interfacce conversazionali:
Il modello di interazione informale basato sul parlato non si presta a spiegazioni dettagliate sulla privacy
Gli utenti spesso non distinguono tra diversi domini funzionali che possono avere diverse implicazioni sulla privacy
La relazione continua con l'intelligenza artificiale conversazionale crea molteplici potenziali momenti di consenso
I sistemi sensibili al contesto possono raccogliere informazioni che gli utenti non intendevano esplicitamente condividere
Le integrazioni con terze parti creano flussi di dati complessi che sono difficili da comunicare in modo chiaro
Le aziende progressiste stanno esplorando nuovi approcci più adatti a queste sfide:
Divulgazione a strati
Invece di sommergere gli utenti con informazioni complete sulla privacy in una sola volta, la divulgazione a strati fornisce informazioni in segmenti comprensibili nei momenti rilevanti:
La configurazione iniziale include opzioni di base sulla privacy
Le implicazioni sulla privacy specifiche per ciascuna funzionalità vengono spiegate quando vengono utilizzate nuove funzionalità
I "check-in" periodici sulla privacy esaminano la raccolta e l'utilizzo dei dati
Le informazioni sulla privacy sono disponibili su richiesta tramite specifici comandi vocali
Questo approccio riconosce che la comprensione della privacy si sviluppa nel tempo attraverso interazioni ripetute piuttosto che da un singolo evento di divulgazione. Consenso contestuale
Andando oltre i modelli binari di opt-in/opt-out, il consenso contestuale richiede l'autorizzazione in momenti decisionali significativi nel percorso dell'utente:
Quando viene raccolto un nuovo tipo di dati personali
Prima di abilitare funzionalità con implicazioni significative per la privacy
Quando si passa dall'elaborazione locale a quella cloud
Prima di condividere i dati con servizi di terze parti
Quando si modifica la modalità di utilizzo dei dati raccolti in precedenza
Fondamentalmente, il consenso contestuale fornisce informazioni sufficienti per decisioni informate senza sopraffare gli utenti, spiegando sia i vantaggi che le implicazioni per la privacy di ciascuna scelta.
Controlli interattivi della privacy
Le interfacce vocali richiedono controlli della privacy accessibili tramite comando vocale. I sistemi leader stanno sviluppando interfacce in linguaggio naturale per la gestione della privacy:
"Quali informazioni memorizzate su di me?"
"Elimina la cronologia dei miei acquisti della settimana scorsa"
"Interrompi il salvataggio delle mie registrazioni vocali"
"Chi ha accesso alle mie domande su argomenti relativi alla salute?"
Questi controlli della privacy conversazionale rendono la protezione più accessibile rispetto ai menu di impostazioni nascosti, sebbene presentino sfide di progettazione specifiche per confermare l'identità e le intenzioni dell'utente.
Privacy Personas e Apprendimento delle Preferenze
Alcuni sistemi stanno esplorando "privacy personas" o profili che raggruppano le scelte di privacy correlate per semplificare il processo decisionale. Altri utilizzano l'apprendimento automatico per comprendere le preferenze di privacy individuali nel tempo, suggerendo impostazioni appropriate in base alle scelte passate, pur mantenendo il controllo esplicito.
Per aziende e sviluppatori, progettare meccanismi efficaci di trasparenza e consenso richiede di riconoscere che gli utenti hanno preferenze di privacy e livelli di alfabetizzazione diversi. Gli approcci di maggior successo tengono conto di questa diversità offrendo percorsi multipli di comprensione e controllo, piuttosto che soluzioni standardizzate.
Con l'integrazione sempre più profonda dell'intelligenza artificiale conversazionale nella vita quotidiana, la creazione di interfacce che comunichino efficacemente le implicazioni sulla privacy senza interrompere l'interazione naturale rimane una sfida di progettazione continua, ma essenziale per la creazione di sistemi affidabili.
Il modello di interazione informale basato sul parlato non si presta a spiegazioni dettagliate sulla privacy
Gli utenti spesso non distinguono tra diversi domini funzionali che possono avere diverse implicazioni sulla privacy
La relazione continua con l'intelligenza artificiale conversazionale crea molteplici potenziali momenti di consenso
I sistemi sensibili al contesto possono raccogliere informazioni che gli utenti non intendevano esplicitamente condividere
Le integrazioni con terze parti creano flussi di dati complessi che sono difficili da comunicare in modo chiaro
Le aziende progressiste stanno esplorando nuovi approcci più adatti a queste sfide:
Divulgazione a strati
Invece di sommergere gli utenti con informazioni complete sulla privacy in una sola volta, la divulgazione a strati fornisce informazioni in segmenti comprensibili nei momenti rilevanti:
La configurazione iniziale include opzioni di base sulla privacy
Le implicazioni sulla privacy specifiche per ciascuna funzionalità vengono spiegate quando vengono utilizzate nuove funzionalità
I "check-in" periodici sulla privacy esaminano la raccolta e l'utilizzo dei dati
Le informazioni sulla privacy sono disponibili su richiesta tramite specifici comandi vocali
Questo approccio riconosce che la comprensione della privacy si sviluppa nel tempo attraverso interazioni ripetute piuttosto che da un singolo evento di divulgazione. Consenso contestuale
Andando oltre i modelli binari di opt-in/opt-out, il consenso contestuale richiede l'autorizzazione in momenti decisionali significativi nel percorso dell'utente:
Quando viene raccolto un nuovo tipo di dati personali
Prima di abilitare funzionalità con implicazioni significative per la privacy
Quando si passa dall'elaborazione locale a quella cloud
Prima di condividere i dati con servizi di terze parti
Quando si modifica la modalità di utilizzo dei dati raccolti in precedenza
Fondamentalmente, il consenso contestuale fornisce informazioni sufficienti per decisioni informate senza sopraffare gli utenti, spiegando sia i vantaggi che le implicazioni per la privacy di ciascuna scelta.
Controlli interattivi della privacy
Le interfacce vocali richiedono controlli della privacy accessibili tramite comando vocale. I sistemi leader stanno sviluppando interfacce in linguaggio naturale per la gestione della privacy:
"Quali informazioni memorizzate su di me?"
"Elimina la cronologia dei miei acquisti della settimana scorsa"
"Interrompi il salvataggio delle mie registrazioni vocali"
"Chi ha accesso alle mie domande su argomenti relativi alla salute?"
Questi controlli della privacy conversazionale rendono la protezione più accessibile rispetto ai menu di impostazioni nascosti, sebbene presentino sfide di progettazione specifiche per confermare l'identità e le intenzioni dell'utente.
Privacy Personas e Apprendimento delle Preferenze
Alcuni sistemi stanno esplorando "privacy personas" o profili che raggruppano le scelte di privacy correlate per semplificare il processo decisionale. Altri utilizzano l'apprendimento automatico per comprendere le preferenze di privacy individuali nel tempo, suggerendo impostazioni appropriate in base alle scelte passate, pur mantenendo il controllo esplicito.
Per aziende e sviluppatori, progettare meccanismi efficaci di trasparenza e consenso richiede di riconoscere che gli utenti hanno preferenze di privacy e livelli di alfabetizzazione diversi. Gli approcci di maggior successo tengono conto di questa diversità offrendo percorsi multipli di comprensione e controllo, piuttosto che soluzioni standardizzate.
Con l'integrazione sempre più profonda dell'intelligenza artificiale conversazionale nella vita quotidiana, la creazione di interfacce che comunichino efficacemente le implicazioni sulla privacy senza interrompere l'interazione naturale rimane una sfida di progettazione continua, ma essenziale per la creazione di sistemi affidabili.
Prova l'IA sul TUO sito web in 60 secondi
Guarda come la nostra IA analizza istantaneamente il tuo sito web e crea un chatbot personalizzato - senza registrazione. Inserisci semplicemente il tuo URL e guarda come funziona!
Pronto in 60 secondi
Nessuna codifica richiesta
100% sicuro
Considerazioni speciali per le popolazioni vulnerabili
L'intelligenza artificiale conversazionale solleva crescenti preoccupazioni in materia di privacy per le popolazioni vulnerabili, le cui esigenze specifiche potrebbero non essere adeguatamente affrontate da approcci generalisti alla privacy. Questi gruppi includono bambini, anziani, persone con disabilità cognitive e persone con una limitata alfabetizzazione tecnologica.
Bambini e privacy
I bambini rappresentano una popolazione particolarmente preoccupante, poiché potrebbero non comprendere le implicazioni sulla privacy, ma interagiscono sempre più con le interfacce conversazionali:
Molti bambini non hanno la capacità di sviluppo necessaria per prendere decisioni informate in materia di privacy
I bambini potrebbero condividere le informazioni più liberamente durante le conversazioni senza comprenderne le potenziali conseguenze
I giovani utenti potrebbero non distinguere tra parlare con un'intelligenza artificiale e con un confidente umano di fiducia
I dati raccolti durante l'infanzia potrebbero potenzialmente seguire gli individui per decenni
Quadri normativi come il COPPA negli Stati Uniti e le disposizioni specifiche del GDPR per i bambini stabiliscono protezioni di base, ma permangono difficoltà di implementazione. La tecnologia di riconoscimento vocale potrebbe avere difficoltà a identificare in modo affidabile gli utenti minorenni, complicando l'adozione di misure di privacy adeguate all'età. I sistemi progettati principalmente per gli adulti potrebbero non spiegare adeguatamente i concetti di privacy in un linguaggio accessibile ai bambini.
Gli sviluppatori che creano IA o funzionalità conversazionali incentrate sui bambini devono considerare approcci specializzati, tra cui:
Impostazioni predefinite di elevata privacy con controlli parentali per eventuali modifiche
Spiegazioni sulla raccolta dati appropriate all'età utilizzando esempi concreti
Periodi di conservazione dei dati limitati per gli utenti minorenni
Uso limitato dei dati che vieta la profilazione o il targeting comportamentale
Indicatori chiari quando le informazioni saranno condivise con i genitori
Anziani e considerazioni sull'accessibilità
Gli anziani e le persone con disabilità possono trarre vantaggi significativi dalle interfacce conversazionali, che spesso offrono modelli di interazione più accessibili rispetto alle interfacce informatiche tradizionali. Tuttavia, possono anche affrontare sfide specifiche in materia di privacy:
Una scarsa familiarità con i concetti tecnologici può influire sulla comprensione della privacy
I deficit cognitivi possono influire sulla capacità di prendere decisioni complesse in materia di privacy
La dipendenza dalle tecnologie assistive può ridurre la capacità pratica di rifiutare i termini sulla privacy
Gli usi correlati alla salute possono coinvolgere dati particolarmente sensibili
La condivisione di dispositivi in contesti di assistenza crea scenari di consenso complessi
Una progettazione responsabile per queste popolazioni richiede un adattamento ponderato senza compromettere l'agency. Gli approcci includono:
Spiegazioni multimodali sulla privacy che presentano le informazioni in vari formati
Scelte semplificate in materia di privacy incentrate sugli impatti pratici piuttosto che sui dettagli tecnici
Rappresentanti di fiducia designati per le decisioni sulla privacy, ove opportuno
Maggiore sicurezza per le funzionalità relative alla salute e all'assistenza
Chiara separazione tra assistenza generale e consulenza medica
Alfabetizzazione digitale e divario nella privacy
Nelle diverse fasce d'età, i diversi livelli di alfabetizzazione digitale e sulla privacy creano quello che i ricercatori chiamano "divario nella privacy", dove chi ha una maggiore comprensione può proteggere meglio le proprie informazioni, mentre altri rimangono più vulnerabili. Le interfacce conversazionali, sebbene potenzialmente più intuitive dell'informatica tradizionale, comportano comunque complesse implicazioni sulla privacy che potrebbero non essere evidenti a tutti gli utenti.
Per colmare questo divario sono necessari approcci che rendano la privacy accessibile senza presupporre conoscenze tecniche:
Spiegazioni sulla privacy incentrate su risultati concreti piuttosto che su meccanismi tecnici
Esempi che illustrano potenziali rischi per la privacy in scenari pertinenti
Divulgazione progressiva che introduce i concetti man mano che diventano rilevanti
Alternative alle informazioni sulla privacy ricche di testo, inclusi formati visivi e audio
In definitiva, la creazione di un'IA conversazionale veramente inclusiva richiede il riconoscimento che le esigenze e la comprensione della privacy variano significativamente da una popolazione all'altra. Approcci univoci lasciano inevitabilmente gli utenti vulnerabili con una protezione inadeguata o esclusi dalle tecnologie utili. Le implementazioni più etiche riconoscono queste differenze e forniscono soluzioni appropriate, pur mantenendo il rispetto dell'autonomia individuale.
Bambini e privacy
I bambini rappresentano una popolazione particolarmente preoccupante, poiché potrebbero non comprendere le implicazioni sulla privacy, ma interagiscono sempre più con le interfacce conversazionali:
Molti bambini non hanno la capacità di sviluppo necessaria per prendere decisioni informate in materia di privacy
I bambini potrebbero condividere le informazioni più liberamente durante le conversazioni senza comprenderne le potenziali conseguenze
I giovani utenti potrebbero non distinguere tra parlare con un'intelligenza artificiale e con un confidente umano di fiducia
I dati raccolti durante l'infanzia potrebbero potenzialmente seguire gli individui per decenni
Quadri normativi come il COPPA negli Stati Uniti e le disposizioni specifiche del GDPR per i bambini stabiliscono protezioni di base, ma permangono difficoltà di implementazione. La tecnologia di riconoscimento vocale potrebbe avere difficoltà a identificare in modo affidabile gli utenti minorenni, complicando l'adozione di misure di privacy adeguate all'età. I sistemi progettati principalmente per gli adulti potrebbero non spiegare adeguatamente i concetti di privacy in un linguaggio accessibile ai bambini.
Gli sviluppatori che creano IA o funzionalità conversazionali incentrate sui bambini devono considerare approcci specializzati, tra cui:
Impostazioni predefinite di elevata privacy con controlli parentali per eventuali modifiche
Spiegazioni sulla raccolta dati appropriate all'età utilizzando esempi concreti
Periodi di conservazione dei dati limitati per gli utenti minorenni
Uso limitato dei dati che vieta la profilazione o il targeting comportamentale
Indicatori chiari quando le informazioni saranno condivise con i genitori
Anziani e considerazioni sull'accessibilità
Gli anziani e le persone con disabilità possono trarre vantaggi significativi dalle interfacce conversazionali, che spesso offrono modelli di interazione più accessibili rispetto alle interfacce informatiche tradizionali. Tuttavia, possono anche affrontare sfide specifiche in materia di privacy:
Una scarsa familiarità con i concetti tecnologici può influire sulla comprensione della privacy
I deficit cognitivi possono influire sulla capacità di prendere decisioni complesse in materia di privacy
La dipendenza dalle tecnologie assistive può ridurre la capacità pratica di rifiutare i termini sulla privacy
Gli usi correlati alla salute possono coinvolgere dati particolarmente sensibili
La condivisione di dispositivi in contesti di assistenza crea scenari di consenso complessi
Una progettazione responsabile per queste popolazioni richiede un adattamento ponderato senza compromettere l'agency. Gli approcci includono:
Spiegazioni multimodali sulla privacy che presentano le informazioni in vari formati
Scelte semplificate in materia di privacy incentrate sugli impatti pratici piuttosto che sui dettagli tecnici
Rappresentanti di fiducia designati per le decisioni sulla privacy, ove opportuno
Maggiore sicurezza per le funzionalità relative alla salute e all'assistenza
Chiara separazione tra assistenza generale e consulenza medica
Alfabetizzazione digitale e divario nella privacy
Nelle diverse fasce d'età, i diversi livelli di alfabetizzazione digitale e sulla privacy creano quello che i ricercatori chiamano "divario nella privacy", dove chi ha una maggiore comprensione può proteggere meglio le proprie informazioni, mentre altri rimangono più vulnerabili. Le interfacce conversazionali, sebbene potenzialmente più intuitive dell'informatica tradizionale, comportano comunque complesse implicazioni sulla privacy che potrebbero non essere evidenti a tutti gli utenti.
Per colmare questo divario sono necessari approcci che rendano la privacy accessibile senza presupporre conoscenze tecniche:
Spiegazioni sulla privacy incentrate su risultati concreti piuttosto che su meccanismi tecnici
Esempi che illustrano potenziali rischi per la privacy in scenari pertinenti
Divulgazione progressiva che introduce i concetti man mano che diventano rilevanti
Alternative alle informazioni sulla privacy ricche di testo, inclusi formati visivi e audio
In definitiva, la creazione di un'IA conversazionale veramente inclusiva richiede il riconoscimento che le esigenze e la comprensione della privacy variano significativamente da una popolazione all'altra. Approcci univoci lasciano inevitabilmente gli utenti vulnerabili con una protezione inadeguata o esclusi dalle tecnologie utili. Le implementazioni più etiche riconoscono queste differenze e forniscono soluzioni appropriate, pur mantenendo il rispetto dell'autonomia individuale.
Considerazioni aziendali: bilanciare innovazione e responsabilità
Per le aziende che sviluppano o implementano l'IA conversazionale, affrontare le sfide legate alla privacy implica decisioni strategiche complesse che bilanciano gli obiettivi aziendali con le responsabilità etiche e i requisiti normativi.
Il business case per la progettazione incentrata sulla privacy
Sebbene a prima vista la protezione della privacy possa sembrare un limite alle opportunità di business, le aziende lungimiranti riconoscono sempre più il valore commerciale di solide pratiche in materia di privacy:
Fiducia come vantaggio competitivo – Con la crescente consapevolezza della privacy, le pratiche di gestione dei dati affidabili diventano un elemento di differenziazione significativo. Le ricerche dimostrano costantemente che i consumatori preferiscono i servizi che ritengono possano proteggere le loro informazioni personali.
Efficienza nella conformità normativa – Integrare la privacy nell'IA conversazionale fin dall'inizio riduce i costosi retrofitting con l'evoluzione delle normative. Questo approccio "privacy by design" rappresenta un significativo risparmio a lungo termine rispetto all'affrontare la privacy in un secondo momento.
Mitigazione del rischio – Le violazioni dei dati e gli scandali sulla privacy comportano costi sostanziali, dalle sanzioni normative al danno reputazionale. La progettazione incentrata sulla privacy riduce questi rischi attraverso la minimizzazione dei dati e adeguate misure di sicurezza.
Accesso al mercato – Solide pratiche in materia di privacy consentono di operare in regioni con normative rigorose, espandendo i mercati potenziali senza richiedere più versioni del prodotto. Questi fattori creano incentivi aziendali convincenti per gli investimenti nella privacy che vanno oltre la mera conformità, in particolare per l'intelligenza artificiale conversazionale, dove la fiducia influisce direttamente sulla propensione degli utenti a interagire con la tecnologia.
Approcci strategici alla raccolta dati
Le aziende devono prendere decisioni ponderate su quali dati i loro sistemi conversazionali raccolgono e come vengono utilizzati:
Minimalismo funzionale: raccogliere solo i dati direttamente necessari per la funzionalità richiesta, con chiari confini tra la raccolta di dati essenziali e quella facoltativa.
Specificità dello scopo: definire scopi ristretti ed espliciti per l'utilizzo dei dati piuttosto che una raccolta ampia e aperta che potrebbe soddisfare esigenze future non specificate.
Differenziazione basata sulla trasparenza: distinguere chiaramente tra i dati utilizzati per funzionalità immediate e quelli utilizzati per il miglioramento del sistema, offrendo agli utenti un controllo separato su questi diversi utilizzi.
Livelli di privacy: offrire opzioni di servizio con diversi compromessi tra privacy e funzionalità, consentendo agli utenti di scegliere il loro equilibrio preferito.
Questi approcci aiutano le aziende a evitare la mentalità del "raccogliere tutto il possibile", che crea sia rischi per la privacy che potenziali esposizioni normative.
Bilanciamento dell'integrazione di prima e terza parte
Le piattaforme conversazionali spesso fungono da gateway per ecosistemi di servizi più ampi, sollevando interrogativi sulla condivisione e l'integrazione dei dati:
Come dovrebbe essere gestito il consenso degli utenti quando le conversazioni si estendono su più servizi?
Chi è responsabile della protezione della privacy nelle esperienze integrate?
Come si possono mantenere le aspettative sulla privacy in modo coerente in un ecosistema?
Quali informazioni sulla privacy dovrebbero essere condivise tra i partner di integrazione?
Le aziende leader affrontano queste sfide attraverso requisiti chiari per i partner, interfacce di privacy standardizzate e divulgazione trasparente dei flussi di dati tra i servizi. Alcune implementano "etichette nutrizionali sulla privacy" che comunicano rapidamente informazioni essenziali sulla privacy prima che gli utenti interagiscano con servizi di terze parti attraverso le loro piattaforme conversazionali.
Creare una governance dei dati sostenibile
Un'efficace protezione della privacy richiede solide strutture di governance che bilancino le esigenze di innovazione con le responsabilità in materia di privacy:
Team interfunzionali per la privacy che includono prospettive di prodotto, ingegneristiche, legali ed etiche
Valutazioni di impatto sulla privacy condotte nelle prime fasi dello sviluppo del prodotto
Audit periodici sulla privacy per verificare la conformità alle policy dichiarate
Strutture di responsabilità chiare che definiscono le responsabilità in materia di privacy all'interno dell'organizzazione
Comitati etici che affrontano le nuove questioni relative alla privacy che emergono nei contesti conversazionali
Questi meccanismi di governance contribuiscono a garantire che le considerazioni sulla privacy siano integrate durante tutto il processo di sviluppo, anziché essere affrontate solo nelle fasi di revisione finale, quando le modifiche diventano costose.
Per le aziende che investono nell'intelligenza artificiale conversazionale, la privacy dovrebbe essere considerata non come un onere per la conformità, ma come un elemento fondamentale dell'innovazione sostenibile. Le aziende che stabiliscono pratiche di privacy affidabili creano le condizioni per una più ampia accettazione e adozione delle proprie tecnologie conversazionali, consentendo in definitiva relazioni con gli utenti più preziose.
Il business case per la progettazione incentrata sulla privacy
Sebbene a prima vista la protezione della privacy possa sembrare un limite alle opportunità di business, le aziende lungimiranti riconoscono sempre più il valore commerciale di solide pratiche in materia di privacy:
Fiducia come vantaggio competitivo – Con la crescente consapevolezza della privacy, le pratiche di gestione dei dati affidabili diventano un elemento di differenziazione significativo. Le ricerche dimostrano costantemente che i consumatori preferiscono i servizi che ritengono possano proteggere le loro informazioni personali.
Efficienza nella conformità normativa – Integrare la privacy nell'IA conversazionale fin dall'inizio riduce i costosi retrofitting con l'evoluzione delle normative. Questo approccio "privacy by design" rappresenta un significativo risparmio a lungo termine rispetto all'affrontare la privacy in un secondo momento.
Mitigazione del rischio – Le violazioni dei dati e gli scandali sulla privacy comportano costi sostanziali, dalle sanzioni normative al danno reputazionale. La progettazione incentrata sulla privacy riduce questi rischi attraverso la minimizzazione dei dati e adeguate misure di sicurezza.
Accesso al mercato – Solide pratiche in materia di privacy consentono di operare in regioni con normative rigorose, espandendo i mercati potenziali senza richiedere più versioni del prodotto. Questi fattori creano incentivi aziendali convincenti per gli investimenti nella privacy che vanno oltre la mera conformità, in particolare per l'intelligenza artificiale conversazionale, dove la fiducia influisce direttamente sulla propensione degli utenti a interagire con la tecnologia.
Approcci strategici alla raccolta dati
Le aziende devono prendere decisioni ponderate su quali dati i loro sistemi conversazionali raccolgono e come vengono utilizzati:
Minimalismo funzionale: raccogliere solo i dati direttamente necessari per la funzionalità richiesta, con chiari confini tra la raccolta di dati essenziali e quella facoltativa.
Specificità dello scopo: definire scopi ristretti ed espliciti per l'utilizzo dei dati piuttosto che una raccolta ampia e aperta che potrebbe soddisfare esigenze future non specificate.
Differenziazione basata sulla trasparenza: distinguere chiaramente tra i dati utilizzati per funzionalità immediate e quelli utilizzati per il miglioramento del sistema, offrendo agli utenti un controllo separato su questi diversi utilizzi.
Livelli di privacy: offrire opzioni di servizio con diversi compromessi tra privacy e funzionalità, consentendo agli utenti di scegliere il loro equilibrio preferito.
Questi approcci aiutano le aziende a evitare la mentalità del "raccogliere tutto il possibile", che crea sia rischi per la privacy che potenziali esposizioni normative.
Bilanciamento dell'integrazione di prima e terza parte
Le piattaforme conversazionali spesso fungono da gateway per ecosistemi di servizi più ampi, sollevando interrogativi sulla condivisione e l'integrazione dei dati:
Come dovrebbe essere gestito il consenso degli utenti quando le conversazioni si estendono su più servizi?
Chi è responsabile della protezione della privacy nelle esperienze integrate?
Come si possono mantenere le aspettative sulla privacy in modo coerente in un ecosistema?
Quali informazioni sulla privacy dovrebbero essere condivise tra i partner di integrazione?
Le aziende leader affrontano queste sfide attraverso requisiti chiari per i partner, interfacce di privacy standardizzate e divulgazione trasparente dei flussi di dati tra i servizi. Alcune implementano "etichette nutrizionali sulla privacy" che comunicano rapidamente informazioni essenziali sulla privacy prima che gli utenti interagiscano con servizi di terze parti attraverso le loro piattaforme conversazionali.
Creare una governance dei dati sostenibile
Un'efficace protezione della privacy richiede solide strutture di governance che bilancino le esigenze di innovazione con le responsabilità in materia di privacy:
Team interfunzionali per la privacy che includono prospettive di prodotto, ingegneristiche, legali ed etiche
Valutazioni di impatto sulla privacy condotte nelle prime fasi dello sviluppo del prodotto
Audit periodici sulla privacy per verificare la conformità alle policy dichiarate
Strutture di responsabilità chiare che definiscono le responsabilità in materia di privacy all'interno dell'organizzazione
Comitati etici che affrontano le nuove questioni relative alla privacy che emergono nei contesti conversazionali
Questi meccanismi di governance contribuiscono a garantire che le considerazioni sulla privacy siano integrate durante tutto il processo di sviluppo, anziché essere affrontate solo nelle fasi di revisione finale, quando le modifiche diventano costose.
Per le aziende che investono nell'intelligenza artificiale conversazionale, la privacy dovrebbe essere considerata non come un onere per la conformità, ma come un elemento fondamentale dell'innovazione sostenibile. Le aziende che stabiliscono pratiche di privacy affidabili creano le condizioni per una più ampia accettazione e adozione delle proprie tecnologie conversazionali, consentendo in definitiva relazioni con gli utenti più preziose.
Formazione e responsabilizzazione degli utenti: oltre le norme sulla privacy
Per creare un'intelligenza artificiale conversazionale realmente rispettosa della privacy, è necessario andare oltre le tradizionali informative sulla privacy per educare attivamente gli utenti e consentire loro di fare scelte consapevoli sui propri dati.
I limiti della comunicazione tradizionale sulla privacy
Gli approcci standard alla comunicazione sulla privacy sono particolarmente carenti per le interfacce conversazionali:
Le informative sulla privacy vengono raramente lette e spesso scritte in un linguaggio giuridico complesso
Le interfacce tradizionali per la gestione della privacy non si adattano bene alle interazioni vocali
Il consenso una tantum non tiene conto della natura continua e in continua evoluzione delle relazioni conversazionali
Le spiegazioni tecniche sulla privacy spesso non riescono a comunicare le implicazioni pratiche per gli utenti
Queste limitazioni creano una situazione in cui è possibile raggiungere una conformità formale (gli utenti "accettano" i termini) senza un consenso informato significativo. Gli utenti potrebbero non comprendere quali dati vengono raccolti, come vengono utilizzati o quale controllo hanno sulle proprie informazioni.
Creare una reale alfabetizzazione sulla privacy
Gli approcci più efficaci si concentrano sulla creazione di una reale comprensione della privacy attraverso:
Formazione tempestiva che fornisce informazioni rilevanti sulla privacy nei momenti chiave anziché in una volta sola
Spiegazioni in linguaggio semplice che si concentrano sui risultati pratici piuttosto che sui meccanismi tecnici
Esempi concreti che illustrano come i dati potrebbero essere utilizzati e le potenziali implicazioni sulla privacy
Dimostrazioni interattive che rendono i concetti di privacy tangibili anziché astratti
Promemoria contestuali su quali dati vengono raccolti durante i diversi tipi di interazioni
Questi approcci riconoscono che l'alfabetizzazione sulla privacy si sviluppa gradualmente attraverso l'esposizione ripetuta e l'esperienza pratica, non attraverso una raccolta di informazioni una tantum.
Progettare per l'azione e il controllo
Oltre alla formazione, gli utenti hanno bisogno di un effettivo controllo sulle proprie informazioni. Gli approcci efficaci includono:
Autorizzazioni granulari che consentono agli utenti di approvare utilizzi specifici anziché un consenso totale
Dashboard sulla privacy che forniscono una visualizzazione chiara dei dati raccolti
Opzioni di eliminazione semplici per la rimozione delle informazioni storiche
Informazioni sull'utilizzo che mostrano come i dati personali influenzano il comportamento del sistema
Scorciatoie sulla privacy per la rapida modifica delle impostazioni comuni
Controlli periodici della privacy che richiedono la revisione delle impostazioni correnti e della raccolta dati
Fondamentalmente, questi controlli devono essere facilmente accessibili tramite l'interfaccia conversazionale stessa, non nascosti in siti web o applicazioni separati che creano difficoltà per gli utenti che utilizzano la voce.
Standard della community e norme sociali
Con la crescente diffusione dell'intelligenza artificiale conversazionale, gli standard della community e le norme sociali svolgono un ruolo sempre più importante nel definire le aspettative in materia di privacy. Le aziende possono contribuire allo sviluppo di norme sane:
Facilitando la formazione sulla privacy tra utenti attraverso forum della community e la condivisione di conoscenze
Evidenziando le migliori pratiche in materia di privacy e riconoscendo gli utenti che le adottano
Creando trasparenza sulle scelte aggregate in materia di privacy per aiutare gli utenti a comprendere le norme della community
Coinvolgendo gli utenti nello sviluppo delle funzionalità per la privacy attraverso feedback e progettazione condivisa
Questi approcci riconoscono che la privacy non è solo una questione individuale, ma un costrutto sociale che si sviluppa attraverso la comprensione e la pratica collettive.
Affinché l'IA conversazionale raggiunga il suo pieno potenziale nel rispetto dei diritti individuali, gli utenti devono diventare partecipanti informati piuttosto che soggetti passivi della raccolta dati. Ciò richiede investimenti costanti nella formazione e nell'empowerment, piuttosto che un obbligo di informativa minimo. Le aziende leader in questo settore rafforzano le relazioni con gli utenti, contribuendo al contempo a un ecosistema complessivo più sano per la tecnologia conversazionale.
I limiti della comunicazione tradizionale sulla privacy
Gli approcci standard alla comunicazione sulla privacy sono particolarmente carenti per le interfacce conversazionali:
Le informative sulla privacy vengono raramente lette e spesso scritte in un linguaggio giuridico complesso
Le interfacce tradizionali per la gestione della privacy non si adattano bene alle interazioni vocali
Il consenso una tantum non tiene conto della natura continua e in continua evoluzione delle relazioni conversazionali
Le spiegazioni tecniche sulla privacy spesso non riescono a comunicare le implicazioni pratiche per gli utenti
Queste limitazioni creano una situazione in cui è possibile raggiungere una conformità formale (gli utenti "accettano" i termini) senza un consenso informato significativo. Gli utenti potrebbero non comprendere quali dati vengono raccolti, come vengono utilizzati o quale controllo hanno sulle proprie informazioni.
Creare una reale alfabetizzazione sulla privacy
Gli approcci più efficaci si concentrano sulla creazione di una reale comprensione della privacy attraverso:
Formazione tempestiva che fornisce informazioni rilevanti sulla privacy nei momenti chiave anziché in una volta sola
Spiegazioni in linguaggio semplice che si concentrano sui risultati pratici piuttosto che sui meccanismi tecnici
Esempi concreti che illustrano come i dati potrebbero essere utilizzati e le potenziali implicazioni sulla privacy
Dimostrazioni interattive che rendono i concetti di privacy tangibili anziché astratti
Promemoria contestuali su quali dati vengono raccolti durante i diversi tipi di interazioni
Questi approcci riconoscono che l'alfabetizzazione sulla privacy si sviluppa gradualmente attraverso l'esposizione ripetuta e l'esperienza pratica, non attraverso una raccolta di informazioni una tantum.
Progettare per l'azione e il controllo
Oltre alla formazione, gli utenti hanno bisogno di un effettivo controllo sulle proprie informazioni. Gli approcci efficaci includono:
Autorizzazioni granulari che consentono agli utenti di approvare utilizzi specifici anziché un consenso totale
Dashboard sulla privacy che forniscono una visualizzazione chiara dei dati raccolti
Opzioni di eliminazione semplici per la rimozione delle informazioni storiche
Informazioni sull'utilizzo che mostrano come i dati personali influenzano il comportamento del sistema
Scorciatoie sulla privacy per la rapida modifica delle impostazioni comuni
Controlli periodici della privacy che richiedono la revisione delle impostazioni correnti e della raccolta dati
Fondamentalmente, questi controlli devono essere facilmente accessibili tramite l'interfaccia conversazionale stessa, non nascosti in siti web o applicazioni separati che creano difficoltà per gli utenti che utilizzano la voce.
Standard della community e norme sociali
Con la crescente diffusione dell'intelligenza artificiale conversazionale, gli standard della community e le norme sociali svolgono un ruolo sempre più importante nel definire le aspettative in materia di privacy. Le aziende possono contribuire allo sviluppo di norme sane:
Facilitando la formazione sulla privacy tra utenti attraverso forum della community e la condivisione di conoscenze
Evidenziando le migliori pratiche in materia di privacy e riconoscendo gli utenti che le adottano
Creando trasparenza sulle scelte aggregate in materia di privacy per aiutare gli utenti a comprendere le norme della community
Coinvolgendo gli utenti nello sviluppo delle funzionalità per la privacy attraverso feedback e progettazione condivisa
Questi approcci riconoscono che la privacy non è solo una questione individuale, ma un costrutto sociale che si sviluppa attraverso la comprensione e la pratica collettive.
Affinché l'IA conversazionale raggiunga il suo pieno potenziale nel rispetto dei diritti individuali, gli utenti devono diventare partecipanti informati piuttosto che soggetti passivi della raccolta dati. Ciò richiede investimenti costanti nella formazione e nell'empowerment, piuttosto che un obbligo di informativa minimo. Le aziende leader in questo settore rafforzano le relazioni con gli utenti, contribuendo al contempo a un ecosistema complessivo più sano per la tecnologia conversazionale.
Soluzioni emergenti e migliori pratiche
Con la crescente consapevolezza delle sfide legate alla privacy nell'IA conversazionale, stanno emergendo approcci innovativi per affrontare queste problematiche, preservando al contempo le funzionalità utili.
Tecnologie per il miglioramento della privacy nell'IA conversazionale
Le innovazioni tecniche specificamente mirate alla privacy nei contesti conversazionali includono:
Enclave di elaborazione locale che eseguono calcoli sensibili sul dispositivo in ambienti sicuri, isolati da altre applicazioni
Tecniche di crittografia omomorfica che consentono l'elaborazione di dati crittografati senza decrittografia, consentendo analisi che preservano la privacy
Dati di training sintetici generati per mantenere le proprietà statistiche delle conversazioni reali senza esporre le interazioni effettive dell'utente
Trascrizione che preserva la privacy e converte il parlato in testo localmente prima di inviare i dati di testo ridotti al minimo per l'elaborazione
Implementazioni di apprendimento federato specificamente ottimizzate per la natura distribuita dei dispositivi conversazionali
Queste tecnologie si trovano in diverse fasi di maturità, alcune delle quali già presenti in prodotti commerciali, mentre altre rimangono principalmente in fase di ricerca.
Standard e framework di settore
Il settore dell'intelligenza artificiale conversazionale sta sviluppando standard e framework condivisi per definire approcci coerenti in materia di privacy:
La Voice Privacy Alliance ha proposto controlli standardizzati sulla privacy e formati di divulgazione per gli assistenti vocali.
L'IEEE ha gruppi di lavoro che sviluppano standard tecnici per la privacy nelle interfacce vocali.
L'Open Voice Network sta creando standard di interoperabilità che includono requisiti di privacy.
Diverse associazioni di settore hanno pubblicato best practice sulla privacy specifiche per i contesti conversazionali.
Questi sforzi collaborativi mirano a stabilire aspettative di base sulla privacy che semplifichino la conformità per gli sviluppatori, garantendo al contempo esperienze utente coerenti su tutte le piattaforme.
Design Pattern per un'esperienza utente conversazionale rispettosa della privacy
I progettisti dell'esperienza utente stanno sviluppando pattern specializzati per la gestione della privacy nelle interfacce conversazionali:
Divulgazione progressiva della privacy che introduce le informazioni in segmenti gestibili
Indicatori di privacy ambientale che utilizzano segnali audio o visivi discreti per indicare quando i sistemi sono in ascolto o in elaborazione
Coreografia del consenso che progetta richieste di autorizzazione naturali che non interrompono il flusso della conversazione
Impostazioni predefinite che preservano la privacy che iniziano con una raccolta minima di dati e si espandono solo con l'approvazione esplicita dell'utente
Meccanismi di oblio che rendono la scadenza e l'eliminazione dei dati parte integrante del modello di interazione
Questi design pattern mirano a rendere le considerazioni sulla privacy parte integrante dell'esperienza conversazionale piuttosto che un livello separato di requisiti di conformità.
Best practice organizzative
Le organizzazioni leader nell'IA conversazionale rispettosa della privacy in genere implementano diverse pratiche chiave:
Professionisti della privacy integrati nei team di sviluppo, non solo negli uffici legali
Valutazioni periodiche del rischio per la privacy durante tutto il ciclo di vita dello sviluppo
Test utente incentrati sulla privacy che valutano esplicitamente la comprensione e il controllo della privacy
Report sulla trasparenza che forniscono informazioni sulle pratiche relative ai dati e sulle richieste di informazioni governative
Audit esterni sulla privacy che convalidano la conformità delle pratiche effettive alle policy dichiarate
Programmi di bug bounty sulla privacy che incoraggiano l'identificazione delle vulnerabilità della privacy
Questi approcci organizzativi garantiscono che le considerazioni sulla privacy rimangano centrali durante lo sviluppo del prodotto, anziché essere considerate in secondo piano durante la revisione legale.
Per gli sviluppatori e le aziende che operano in questo settore, queste soluzioni emergenti forniscono indicazioni preziose per la creazione di un'IA conversazionale che rispetti la privacy offrendo al contempo esperienze utente coinvolgenti. Sebbene un singolo approccio risolva tutte le sfide relative alla privacy, una combinazione ponderata di pratiche tecniche, di progettazione e organizzative può migliorare sostanzialmente i risultati in materia di privacy.
Tecnologie per il miglioramento della privacy nell'IA conversazionale
Le innovazioni tecniche specificamente mirate alla privacy nei contesti conversazionali includono:
Enclave di elaborazione locale che eseguono calcoli sensibili sul dispositivo in ambienti sicuri, isolati da altre applicazioni
Tecniche di crittografia omomorfica che consentono l'elaborazione di dati crittografati senza decrittografia, consentendo analisi che preservano la privacy
Dati di training sintetici generati per mantenere le proprietà statistiche delle conversazioni reali senza esporre le interazioni effettive dell'utente
Trascrizione che preserva la privacy e converte il parlato in testo localmente prima di inviare i dati di testo ridotti al minimo per l'elaborazione
Implementazioni di apprendimento federato specificamente ottimizzate per la natura distribuita dei dispositivi conversazionali
Queste tecnologie si trovano in diverse fasi di maturità, alcune delle quali già presenti in prodotti commerciali, mentre altre rimangono principalmente in fase di ricerca.
Standard e framework di settore
Il settore dell'intelligenza artificiale conversazionale sta sviluppando standard e framework condivisi per definire approcci coerenti in materia di privacy:
La Voice Privacy Alliance ha proposto controlli standardizzati sulla privacy e formati di divulgazione per gli assistenti vocali.
L'IEEE ha gruppi di lavoro che sviluppano standard tecnici per la privacy nelle interfacce vocali.
L'Open Voice Network sta creando standard di interoperabilità che includono requisiti di privacy.
Diverse associazioni di settore hanno pubblicato best practice sulla privacy specifiche per i contesti conversazionali.
Questi sforzi collaborativi mirano a stabilire aspettative di base sulla privacy che semplifichino la conformità per gli sviluppatori, garantendo al contempo esperienze utente coerenti su tutte le piattaforme.
Design Pattern per un'esperienza utente conversazionale rispettosa della privacy
I progettisti dell'esperienza utente stanno sviluppando pattern specializzati per la gestione della privacy nelle interfacce conversazionali:
Divulgazione progressiva della privacy che introduce le informazioni in segmenti gestibili
Indicatori di privacy ambientale che utilizzano segnali audio o visivi discreti per indicare quando i sistemi sono in ascolto o in elaborazione
Coreografia del consenso che progetta richieste di autorizzazione naturali che non interrompono il flusso della conversazione
Impostazioni predefinite che preservano la privacy che iniziano con una raccolta minima di dati e si espandono solo con l'approvazione esplicita dell'utente
Meccanismi di oblio che rendono la scadenza e l'eliminazione dei dati parte integrante del modello di interazione
Questi design pattern mirano a rendere le considerazioni sulla privacy parte integrante dell'esperienza conversazionale piuttosto che un livello separato di requisiti di conformità.
Best practice organizzative
Le organizzazioni leader nell'IA conversazionale rispettosa della privacy in genere implementano diverse pratiche chiave:
Professionisti della privacy integrati nei team di sviluppo, non solo negli uffici legali
Valutazioni periodiche del rischio per la privacy durante tutto il ciclo di vita dello sviluppo
Test utente incentrati sulla privacy che valutano esplicitamente la comprensione e il controllo della privacy
Report sulla trasparenza che forniscono informazioni sulle pratiche relative ai dati e sulle richieste di informazioni governative
Audit esterni sulla privacy che convalidano la conformità delle pratiche effettive alle policy dichiarate
Programmi di bug bounty sulla privacy che incoraggiano l'identificazione delle vulnerabilità della privacy
Questi approcci organizzativi garantiscono che le considerazioni sulla privacy rimangano centrali durante lo sviluppo del prodotto, anziché essere considerate in secondo piano durante la revisione legale.
Per gli sviluppatori e le aziende che operano in questo settore, queste soluzioni emergenti forniscono indicazioni preziose per la creazione di un'IA conversazionale che rispetti la privacy offrendo al contempo esperienze utente coinvolgenti. Sebbene un singolo approccio risolva tutte le sfide relative alla privacy, una combinazione ponderata di pratiche tecniche, di progettazione e organizzative può migliorare sostanzialmente i risultati in materia di privacy.
Il futuro della privacy nell'intelligenza artificiale conversazionale
As we look ahead, several trends are likely to shape the evolving relationship between conversational AI and privacy.
From Centralized to Distributed Intelligence
The architecture of conversational AI systems is increasingly shifting from fully cloud-based approaches toward more distributed models:
Personal AI agents that run primarily on user devices, maintaining private knowledge bases about individual preferences and patterns
Hybrid processing systems that handle sensitive functions locally while leveraging cloud resources for compute-intensive tasks
User-controlled cloud instances where individuals own their data and the processing resources that operate on it
Decentralized learning approaches that improve AI systems without centralizing user data
These architectural shifts fundamentally change the privacy equation by keeping more personal data under user control rather than aggregating it in centralized corporate repositories.
Evolving Regulatory Approaches
Privacy regulation for conversational AI continues to develop, with several emerging trends:
AI-specific regulations that address unique challenges beyond general data protection frameworks
Global convergence around core privacy principles despite regional variations in specific requirements
Certification programs providing standardized ways to verify privacy protections
Algorithmic transparency requirements mandating explanation of how AI systems use personal data
These regulatory developments will likely establish clearer boundaries for conversational AI while potentially creating more predictable compliance environments for developers.
Shifting User Expectations
User attitudes toward privacy in conversational contexts are evolving as experience with these technologies grows:
Increasing sophistication about privacy trade-offs and the value of personal data
Greater demand for transparency about how conversational data improves AI systems
Rising expectations for granular control over different types of personal information
Growing concern about emotional and psychological profiles created through conversation analysis
These evolving attitudes will shape market demand for privacy features and potentially reward companies that offer stronger protections.
Ethical AI and Value Alignment
Beyond legal compliance, conversational AI is increasingly evaluated against broader ethical frameworks:
Value alignment ensuring AI systems respect user privacy values even when not legally required
Distributive justice addressing privacy disparities across different user groups
Intergenerational equity considering long-term privacy implications of data collected today
Collective privacy interests recognizing that individual privacy choices affect broader communities
These ethical considerations extend privacy discussions beyond individual rights to consider societal impacts and collective interests that may not be fully addressed by individual choice frameworks.
Privacy as Competitive Advantage
As privacy awareness grows, market dynamics around conversational AI are evolving:
Privacy-focused alternatives gaining traction against data-intensive incumbents
Premium positioning for high-privacy options in various market segments
Increased investment in privacy-enhancing technologies to enable differentiation
Enterprise buyers prioritizing privacy features in procurement decisions
These market forces create economic incentives for privacy innovation beyond regulatory compliance, potentially accelerating development of privacy-respecting alternatives.
The future of privacy in conversational AI will be shaped by the interplay of these technological, regulatory, social, and market forces. While perfect privacy solutions remain elusive, the direction of development suggests increasing options for users who seek more privacy-respecting conversational experiences.
For developers, businesses, and users engaged with these systems, staying informed about emerging approaches and actively participating in shaping privacy norms and expectations will be essential as conversational AI becomes an increasingly central part of our digital lives.
Conclusion: Toward Responsible Conversational AI
As conversational AI continues its rapid evolution and integration into our daily lives, the privacy challenges we've explored take on increasing urgency. These systems promise tremendous benefits—more natural human-computer interaction, accessibility for those who struggle with traditional interfaces, and assistance that adapts to individual needs. Realizing these benefits while protecting fundamental privacy rights requires thoughtful navigation of complex trade-offs.
The path forward isn't about choosing between functionality and privacy as mutually exclusive options. Rather, it involves creative problem-solving to design systems that deliver valuable capabilities while respecting privacy boundaries. This requires technical innovation, thoughtful design, organizational commitment, and appropriate regulation working in concert.
For developers, the challenge lies in creating systems that collect only necessary data, process it with appropriate safeguards, and provide meaningful transparency and control. For businesses, it means recognizing privacy as a core value proposition rather than a compliance burden. For users, it involves becoming more informed about privacy implications and expressing preferences through both settings choices and market decisions.
Perhaps most importantly, advancing privacy-respecting conversational AI requires ongoing dialogue between all stakeholders—technologists, businesses, policymakers, privacy advocates, and users themselves. These conversations need to address not just what's technically possible or legally required, but what kind of relationship we want with the increasingly intelligent systems that mediate our digital experiences.
The decisions we make today about conversational AI privacy will shape not just current products but the trajectory of human-AI interaction for years to come. By approaching these challenges thoughtfully, we can create conversational systems that earn trust through respect for privacy rather than demanding trust despite privacy concerns.
The most successful conversational AI won't be the systems that collect the most data or even those that provide the most functionality, but those that strike a thoughtful balance—delivering valuable assistance while respecting the fundamental human need for privacy and control over personal information. Achieving this balance is not just good ethics; it's the foundation for sustainable, beneficial AI that serves human flourishing.
From Centralized to Distributed Intelligence
The architecture of conversational AI systems is increasingly shifting from fully cloud-based approaches toward more distributed models:
Personal AI agents that run primarily on user devices, maintaining private knowledge bases about individual preferences and patterns
Hybrid processing systems that handle sensitive functions locally while leveraging cloud resources for compute-intensive tasks
User-controlled cloud instances where individuals own their data and the processing resources that operate on it
Decentralized learning approaches that improve AI systems without centralizing user data
These architectural shifts fundamentally change the privacy equation by keeping more personal data under user control rather than aggregating it in centralized corporate repositories.
Evolving Regulatory Approaches
Privacy regulation for conversational AI continues to develop, with several emerging trends:
AI-specific regulations that address unique challenges beyond general data protection frameworks
Global convergence around core privacy principles despite regional variations in specific requirements
Certification programs providing standardized ways to verify privacy protections
Algorithmic transparency requirements mandating explanation of how AI systems use personal data
These regulatory developments will likely establish clearer boundaries for conversational AI while potentially creating more predictable compliance environments for developers.
Shifting User Expectations
User attitudes toward privacy in conversational contexts are evolving as experience with these technologies grows:
Increasing sophistication about privacy trade-offs and the value of personal data
Greater demand for transparency about how conversational data improves AI systems
Rising expectations for granular control over different types of personal information
Growing concern about emotional and psychological profiles created through conversation analysis
These evolving attitudes will shape market demand for privacy features and potentially reward companies that offer stronger protections.
Ethical AI and Value Alignment
Beyond legal compliance, conversational AI is increasingly evaluated against broader ethical frameworks:
Value alignment ensuring AI systems respect user privacy values even when not legally required
Distributive justice addressing privacy disparities across different user groups
Intergenerational equity considering long-term privacy implications of data collected today
Collective privacy interests recognizing that individual privacy choices affect broader communities
These ethical considerations extend privacy discussions beyond individual rights to consider societal impacts and collective interests that may not be fully addressed by individual choice frameworks.
Privacy as Competitive Advantage
As privacy awareness grows, market dynamics around conversational AI are evolving:
Privacy-focused alternatives gaining traction against data-intensive incumbents
Premium positioning for high-privacy options in various market segments
Increased investment in privacy-enhancing technologies to enable differentiation
Enterprise buyers prioritizing privacy features in procurement decisions
These market forces create economic incentives for privacy innovation beyond regulatory compliance, potentially accelerating development of privacy-respecting alternatives.
The future of privacy in conversational AI will be shaped by the interplay of these technological, regulatory, social, and market forces. While perfect privacy solutions remain elusive, the direction of development suggests increasing options for users who seek more privacy-respecting conversational experiences.
For developers, businesses, and users engaged with these systems, staying informed about emerging approaches and actively participating in shaping privacy norms and expectations will be essential as conversational AI becomes an increasingly central part of our digital lives.
Conclusion: Toward Responsible Conversational AI
As conversational AI continues its rapid evolution and integration into our daily lives, the privacy challenges we've explored take on increasing urgency. These systems promise tremendous benefits—more natural human-computer interaction, accessibility for those who struggle with traditional interfaces, and assistance that adapts to individual needs. Realizing these benefits while protecting fundamental privacy rights requires thoughtful navigation of complex trade-offs.
The path forward isn't about choosing between functionality and privacy as mutually exclusive options. Rather, it involves creative problem-solving to design systems that deliver valuable capabilities while respecting privacy boundaries. This requires technical innovation, thoughtful design, organizational commitment, and appropriate regulation working in concert.
For developers, the challenge lies in creating systems that collect only necessary data, process it with appropriate safeguards, and provide meaningful transparency and control. For businesses, it means recognizing privacy as a core value proposition rather than a compliance burden. For users, it involves becoming more informed about privacy implications and expressing preferences through both settings choices and market decisions.
Perhaps most importantly, advancing privacy-respecting conversational AI requires ongoing dialogue between all stakeholders—technologists, businesses, policymakers, privacy advocates, and users themselves. These conversations need to address not just what's technically possible or legally required, but what kind of relationship we want with the increasingly intelligent systems that mediate our digital experiences.
The decisions we make today about conversational AI privacy will shape not just current products but the trajectory of human-AI interaction for years to come. By approaching these challenges thoughtfully, we can create conversational systems that earn trust through respect for privacy rather than demanding trust despite privacy concerns.
The most successful conversational AI won't be the systems that collect the most data or even those that provide the most functionality, but those that strike a thoughtful balance—delivering valuable assistance while respecting the fundamental human need for privacy and control over personal information. Achieving this balance is not just good ethics; it's the foundation for sustainable, beneficial AI that serves human flourishing.